DataSophon
VISION
It is committed to rapidly implementing the deployment, management, monitoring and automatic operation and maintenance of the big data cloud native platform, helping you quickly build a stable, efficient, elastic and scalable big data cloud native platform.
What is DataSophon
The Three-Body Problem, a Hugo Award-winning work of the world's highest science fiction literature, is known for its stunning "hard science fiction" style, and its author Liu Cixin is credited with "single-handedly raising Chinese science fiction to a world-class level".
As a very important role in the Triad, the Sophon is a two-dimensional unfolding of the nine-dimensional proton, which is transformed into a supercomputer through circuit etching and then transferred back to the microscopic eleventh dimension to monitor every human movement and use quantum entanglement to achieve instantaneous communication to report to the Triad civilization four light years away. To put it bluntly, the Sophon is a AI real-time remote monitoring and management platform deployed by the Triad civilization on Earth.
DataSophon is a similar management platform. Unlike the Sophon, which aims to limit human's basic science and hinder human's technology development, DataSophon is dedicated to automatical monitoring, operation and management of Big Data infrastructure components and nodes, helping you to quickly build a stable, efficient Big Data cluster service.
Key Features
- Easy to deploy, can quickly complete the deployment of about 300 nodes of big data clusters.
- The minimalist architecture design makes it easy to adapt to various complex environments, supports mixed deployment of arm and x86 machines, and supports commonly used Linux eco operating systems.
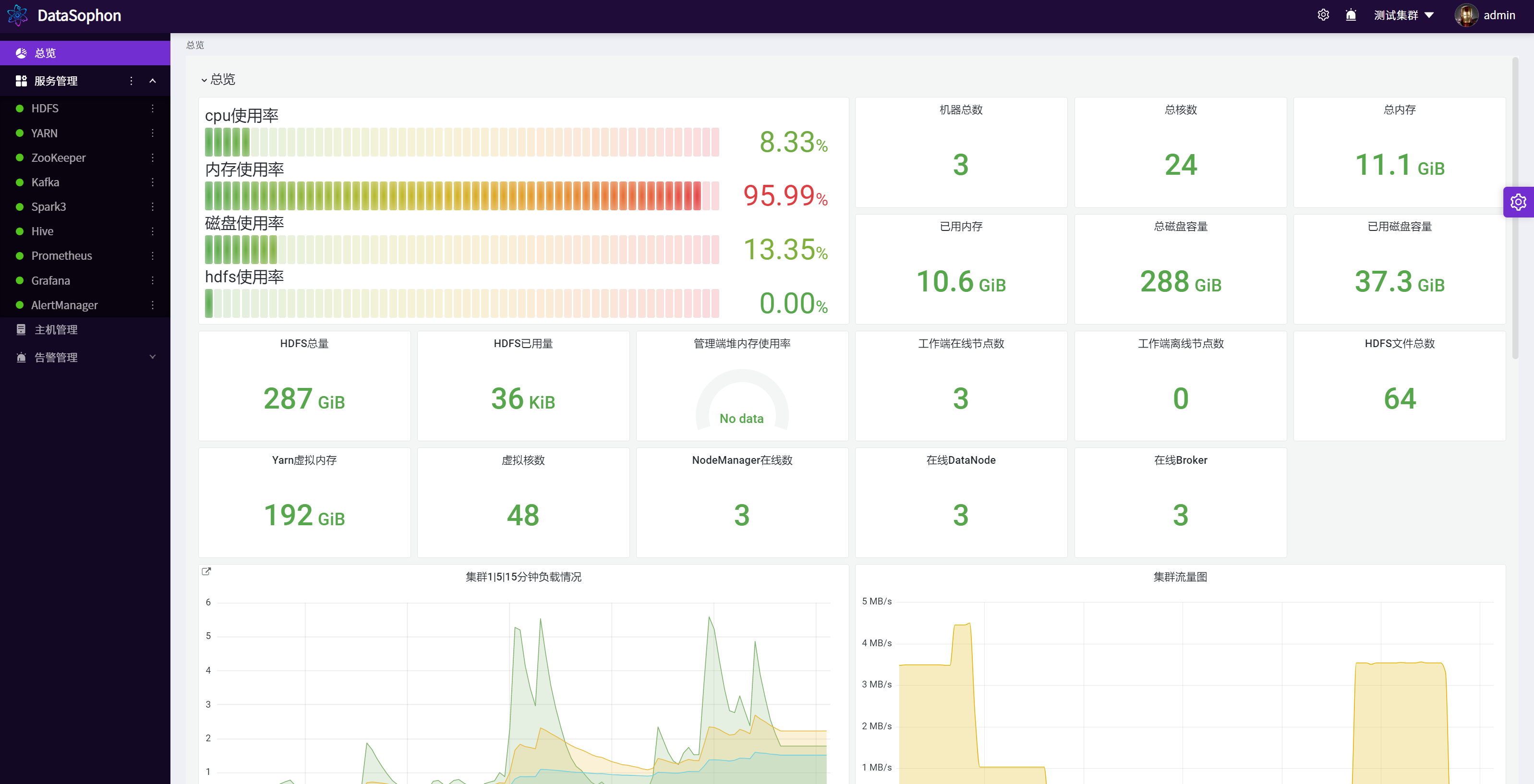
- The monitoring indicators are comprehensive and rich. Based on production practice, the monitoring indicators most concerned by users are displayed.
- Flexible and convenient alarm service, which can realize user-defined alarm groups and indicators.
- Strong scalability, users can integrate or upgrade big data components through configuration.
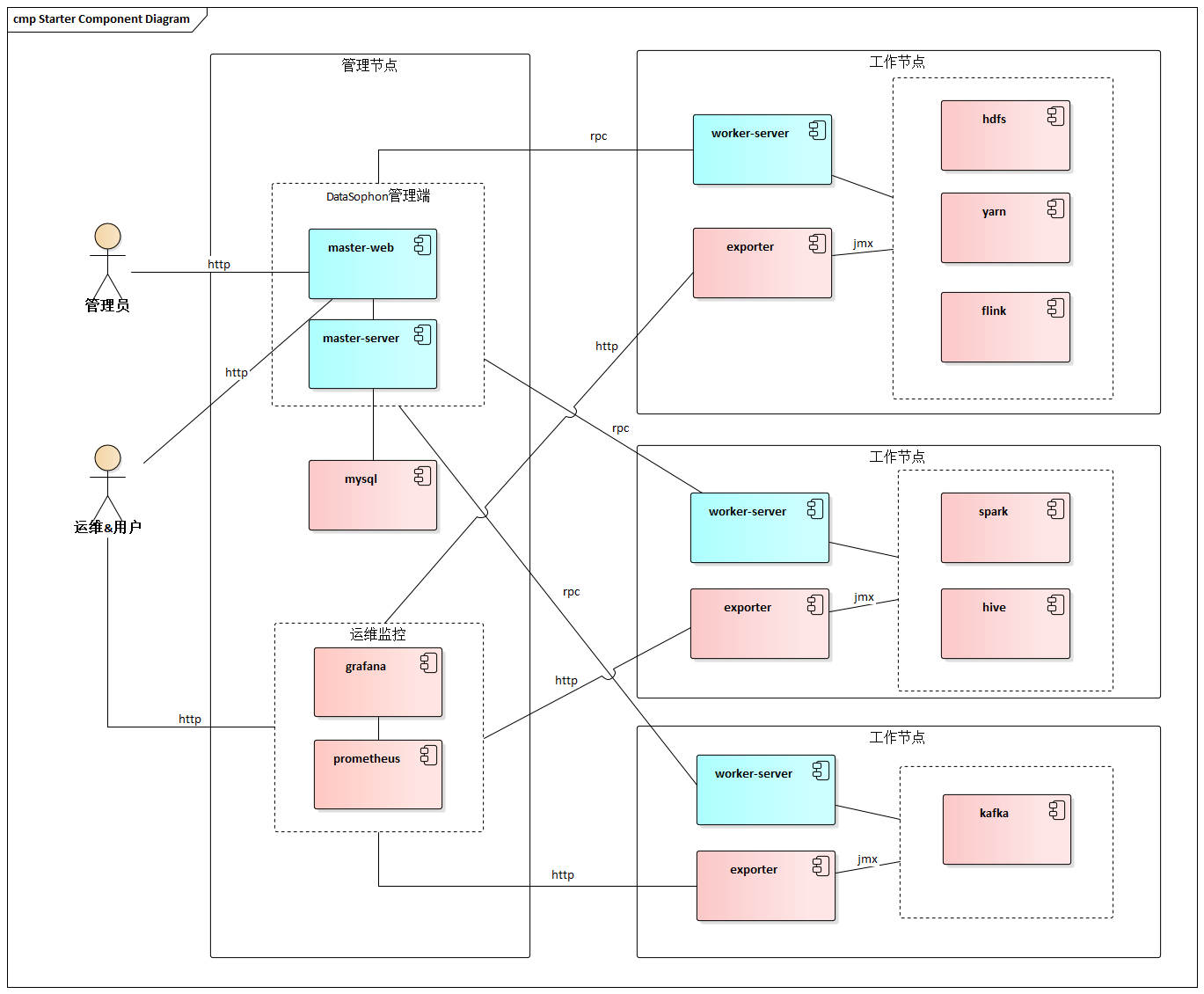
Architecture
Integration Components
All integration components have been tested for compatibility, and have been running stably in a 300+node scale big data cluster, with a daily processing volume of about 400 billion pieces of data.
| Num | Name | Version | Description |
|---|---|---|---|
| 1 | HDFS | 3.3.3 | Distributed big data storage |
| 2 | YARN | 3.3.3 | Distributed resource scheduling and management platform |
| 3 | ZooKeeper | 3.5.10 | Distributed coordination system |
| 4 | FLINK | 1.15.2 | Real time computing engine |
| 5 | DolphoinScheduler | 3.1.1 | Distributed and extensible visual workflow task scheduling platform |
| 6 | StreamPark | 1.2.3 | Streaming processing rapid development framework, cloud native platform with streaming batch integration and lake warehouse integration |
| 7 | Spark | 3.1.3 | Distributed computing system |
| 8 | Hive | 3.1.0 | Offline data warehouse |
| 9 | Kafka | 2.4.1 | High throughput distributed publish subscribe message system |
| 10 | Trino | 367 | Distributed Sql interactive query engine |
| 11 | StarRocks | 2.2.2 | New generation of fast full scene MPP database |
| 12 | Hbase | 2.0.2 | Distributed column storage database |
| 13 | Ranger | 2.1.0 | Permission control framework |
| 14 | ElasticSearch | 7.16.2 | High performance search engine |
| 15 | Prometheus | 2.17.2 | High performance monitoring index acquisition and alarm system |
| 16 | Grafana | 9.1.6 | Monitoring Analysis and Data Visualization Suite |
| 17 | AlertManager | 0.23.0 | Alarm notification management system |